cuda基础
CUDA并行计算基础,包括术语解释、显存分配、层级结构和内存模型。
术语
Streaming Processor (SP):GPU 中的基本执行单元,具备并行执行能力。
Streaming Multiprocessor (SM):由一组 SP 构成的更高层级计算单元,负责控制和组织在 SP 上执行的任务。
Thread:线程,CUDA 的最小执行单位。
Block:线程块,由一组线程组成,通常最多包含 1024 个 thread。
Grid:由多个 Block 构成的集合。
Warp:并行执行的一组线程,通常为 32 个 thread。遵循 SIMD(Single Instruction, Multiple Data)模型,即 32 个线程在不同数据上执行相同指令。
补充关系理解:
- 每个 SM 会处理一定数量的 Blocks
- 每个 SP 可以处理多个 Thread
CUDA 中的显存分配
cudaMallocManaged() 会返回一个既可以被主机(CPU)代码访问,也可以被设备(GPU)代码访问的指针。
如果数据当前位于 CPU 内存中,GPU 在计算时可能发生频繁的缺页,并将数据页拷贝到 GPU,从而降低性能。
cudaMemPrefetchAsync() 可以在内核执行前,将数据提前迁移到 GPU,以减少运行时的开销。
层级结构
Compute Capability < 9.0:
1
2
3
Grid
└── Block
└── Thread
Compute Capability ≥ 9.0:
1
2
3
4
Grid
└── Cluster
└── Block
└── Thread
说明:
- 一个 Cluster 中的 Blocks 一定会被调度到同一个 GPC 上
- 可以使用分布式共享内存,使数据共享更高效
Cluster 维度的指定方式:
- 编译期:
__cluster_dims__(X, Y, Z) - 运行时:
cudaLaunchKernelEx()
内存模型
- Host(CPU)内存:通常通过
new()、malloc()分配 - Device(GPU)内存:通过
cudaMalloc()分配
二者默认不能直接互相访问。
Unified Memory:CPU 和 GPU 都可以访问同一块内存。
硬件执行模型
SIMT
SIMT(Single Instruction, Multiple Thread)
GPU 不像 CPU 那样具备复杂的控制逻辑(如分支预测、推测执行),而是以相对简单的方式顺序发出指令。
Warp
- Warp 是由 32 个线程组成的执行单位
- 同一个 Warp 内的线程从相同的程序地址开始执行
- 每个线程拥有独立的寄存器(包括程序计数器等),因此可以发生分支
调度过程:
- 当 SM 获取多个 Thread Blocks 时,会按线程 ID 顺序将线程划分为 Warp(每 32 个一组)
- 每个 Warp 由 Warp 调度器进行调度执行
执行特性:
- 一个 Warp 在某一时刻只能执行一条相同的指令
- 当 32 个线程执行路径一致时,性能最佳
- 若发生分支,不在当前执行路径上的线程会被暂时禁用,例如
if (threadIdx.x % 2 == 0) - warp 中参与当前指令执行的线程称为“激活”,未参与执行的称为“非激活”
- 线程处于非激活状态的原因包括:提前退出、执行了不同的分支路径,或位于未填满(不足 32 个线程)的最后一个 warp 中
补充:
- 不同 Warp 之间相互独立执行
- 可并行执行的 block 和 warp 数量,取决于寄存器和共享内存的使用情况(包括 kernel 的需求以及每个多处理器可用的资源)
Parallel Reduction
问题:求一个数组中所有元素的和
版本1
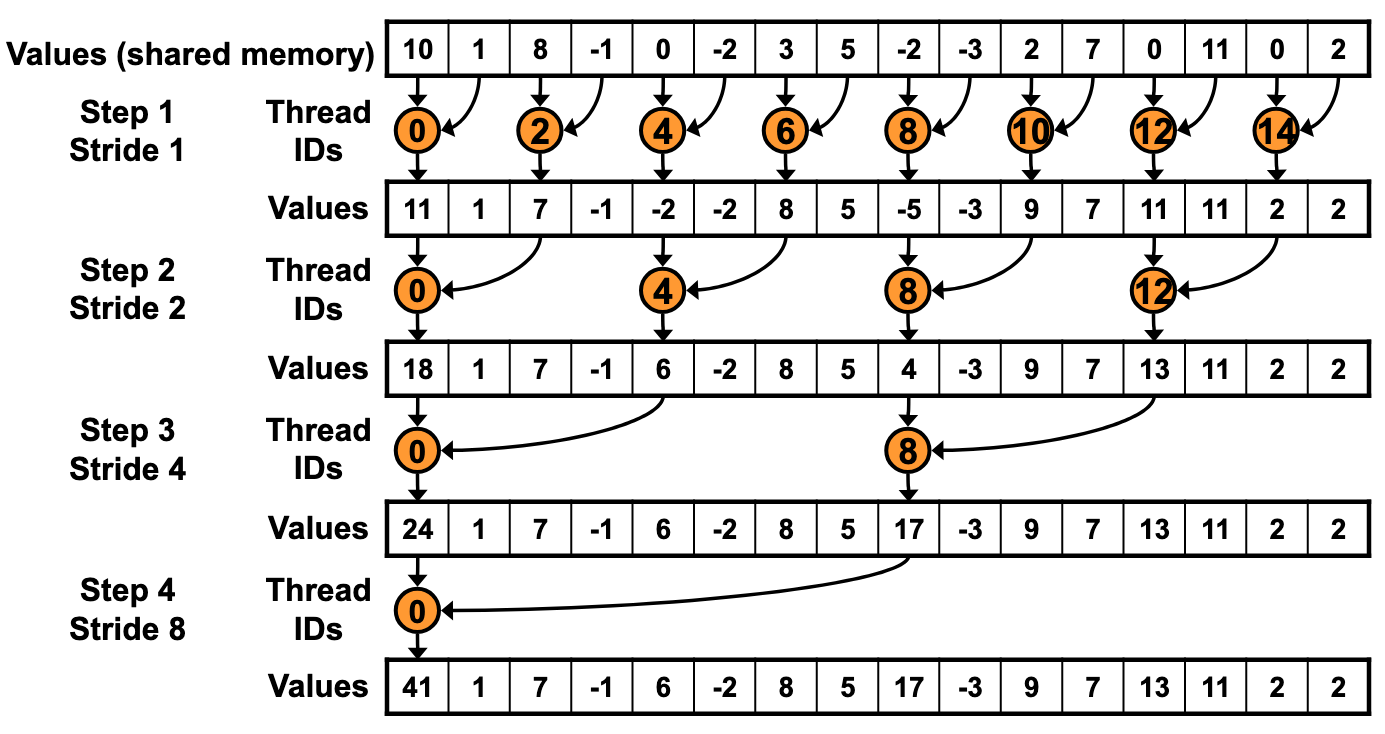
最简单的方法:每个thread负责Values中 下标等于自己tid的数据
比如step1时,相加结果保存到0,2,4,…… 那么相加的运算也由tid为0,2,4,……的thread负责
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
__global__ void reduce0(int *g_idata, int *g_odata) {
extern __shared__ int sdata[];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
__syncthreads();
// do reduction in shared mem
for (unsigned int s = 1; s < blockDim.x; s *= 2) {
if (tid % (2 * s) == 0) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
[!WARNING]
if (tid % (2 * s) == 0)这种判断,造成了warp分支发散导致性能下降直接用tid作为下标,对应关系:
这样基数tid的线程就得不到运行
取模操作非常耗时
版本2
[!NOTE]
tid取值为0,1,2,3,……而每次存储相加结果的下标,与tid有如下关系:
Step1: tid的2倍
Step2: tid的4倍
……
为了避免warp发散,可以做如下设计:
1
2
3
4
5
6
7
8
for (unsigned int s = 1; s < blockDim.x; s *= 2) {
int index = 2 * s * tid;
if (index < blockDim.x) {
sdata[index] += sdata[index + s];
}
__syncthreads();
}
现在前一半线程运行,后一半线程不运行,分支比版本1更规整
版本3
[!WARNING]
版本2虽然做到了线程连续,一定程度提升了性能,但数据访问却不是连续的
问题出在index计算,每个线程在步长较大时,访问sdata可能跨度极大,导致cache利用不佳
所以我们直接更改算法,每个Step将相加结果保存在连续的存储空间中
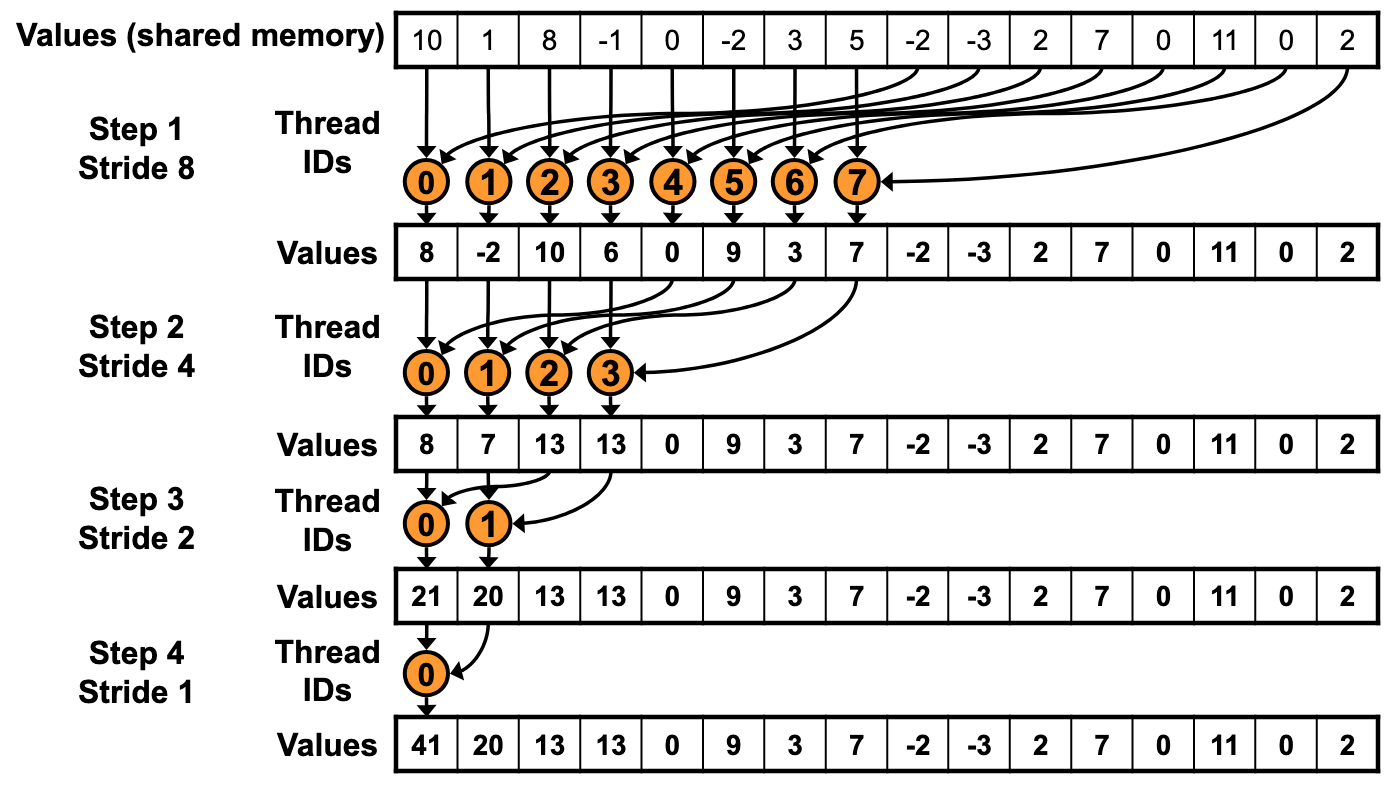
1
2
3
4
5
6
for (unsigned int s = blockDim.x/2; s > 0; s >>= 1) {
if (tid < s) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
版本4
[!WARNING]
虽然这种写法让线程分支更加规整,但
if (tid < s)仍然意味着在每一轮归约中有一半的线程处于空闲状态,从硬件利用率角度来看是一种浪费。一个自然的优化思路是:既然只需要一半的线程就可以完成当前 block 的归约工作,那么可以让这些线程在一开始就承担更多的数据处理任务,从而提高整体计算密度。
具体来说,可以让每个线程在加载阶段同时处理两个数据元素(而不是一个),先在寄存器中完成一次局部累加,再写入 shared memory。这样一来,每个 block 实际上处理的数据量翻倍,但线程数量不变,从而减少了后续归约阶段中线程空闲带来的浪费。
1
2
3
4
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x * (blockDim.x * 2) + threadIdx.x;
sdata[tid] = g_idata[i] + g_idata[i + blockDim.x];
__syncthreads();
版本5
[!WARNING]
注意到,s <= 32时,由于有
if (tid < s)的判断,此时只有一个warp了一个warp中的threads,遵循SIMD规则。他们执行的都是同一条指令,但对应的不同数据。执行顺序是硬件保证一致的
所以,我们没必要
__syncthreads()了,因为一个warp中的threads一定是一起执行完某条指令才会继续执行我们也没必要进行
if (tid < s)的判断了对于一个warp的处理,可以直接展开,而不是用循环
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
__device__ void warpReduce(volatile int* sdata, int tid) {
sdata[tid] += sdata[tid + 32];
sdata[tid] += sdata[tid + 16];
sdata[tid] += sdata[tid + 8];
sdata[tid] += sdata[tid + 4];
sdata[tid] += sdata[tid + 2];
sdata[tid] += sdata[tid + 1];
}
...
for (unsigned int s = blockDim.x / 2; s > 32; s >>= 1) {
if (tid < s) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
if (tid < 32) warpReduce(sdata, tid);
[!NOTE]
这对所有warps都有效,而不只是最后一个warp
如果不展开的话,所有warps都会执行循环,进行if判断,非常低效
版本6
[!WARNING]
版本5的代码,看上去有越界的风险
比如blockSize如果大于等于32,那么
sdata[tid] += sdata[tid + 32];就可能会越界所以必须对blockSize进行判断
这里利用c++的模板,可以实现编译期确定blockSize和运行分支
1
2
3
4
5
6
7
8
9
template <unsigned int blockSize>
__device__ void warpReduce(volatile int* sdata, unsigned int tid) {
if (blockSize >= 64) sdata[tid] += sdata[tid + 32];
if (blockSize >= 32) sdata[tid] += sdata[tid + 16];
if (blockSize >= 16) sdata[tid] += sdata[tid + 8];
if (blockSize >= 8) sdata[tid] += sdata[tid + 4];
if (blockSize >= 4) sdata[tid] += sdata[tid + 2];
if (blockSize >= 2) sdata[tid] += sdata[tid + 1];
}
这样,编译器会直接删除不满足的 if 分支。如果编译期发现blockSize是小于64的,那么第一条语句会被删除,只剩下后面5个相加语句
并且,GPU限制一个block最多512threads(这在 今天的GPU架构中可能并不成立,即便不是512,总是个不大的数字就对了),我们甚至可以完全展开代码,实现没有循环的版本,消除分支预测开销
1
2
3
4
5
6
7
8
9
10
if (blockSize >= 512) {
if (tid < 256) { sdata[tid] += sdata[tid + 256]; } __syncthreads();
}
if (blockSize >= 256) {
if (tid < 128) { sdata[tid] += sdata[tid + 128]; } __syncthreads();
}
if (blockSize >= 128) {
if (tid < 64) { sdata[tid] += sdata[tid + 64]; } __syncthreads();
}
if (tid < 32) warpReduce<blockSize>(sdata, tid);
其实只是根据blockSize的大小,把之前的for循环展开写罢了。这样可以大大降低分支预测开销
[!WARNING]
但是c++模板需要blockSize是一个编译期常量,但我们只能通过blockDim.x获得,这显然是一个运行时确定的量
我们只需要用switch语句枚举即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
switch (threadsPerBlock)
{
case 512:
reduce5<512><<<dimGrid, dimBlock, smemSize>>>(d_idata, d_odata);
break;
case 256:
reduce5<256><<<dimGrid, dimBlock, smemSize>>>(d_idata, d_odata);
break;
case 128:
reduce5<128><<<dimGrid, dimBlock, smemSize>>>(d_idata, d_odata);
break;
case 64:
reduce5<64><<<dimGrid, dimBlock, smemSize>>>(d_idata, d_odata);
break;
case 32:
reduce5<32><<<dimGrid, dimBlock, smemSize>>>(d_idata, d_odata);
break;
case 16:
reduce5<16><<<dimGrid, dimBlock, smemSize>>>(d_idata, d_odata);
break;
case 8:
reduce5<8><<<dimGrid, dimBlock, smemSize>>>(d_idata, d_odata);
break;
case 4:
reduce5<4><<<dimGrid, dimBlock, smemSize>>>(d_idata, d_odata);
break;
case 2:
reduce5<2><<<dimGrid, dimBlock, smemSize>>>(d_idata, d_odata);
break;
case 1:
reduce5<1><<<dimGrid, dimBlock, smemSize>>>(d_idata, d_odata);
break;
default:
// 如果传入非 2 的幂的大小,可以 fallback 到 256 或报错
printf("Error: Unsupported block size %d\n", threadsPerBlock);
// 或者 fallback 处理:
// reduce5<256><<<dimGrid, dimBlock, smemSize>>>(d_idata, d_odata);
break;
}
版本7
线程是否我们定义多少,就会创建多少?
从逻辑视角看:是的。当我们启动 Kernel 时,定义的线程数决定了 threadIdx 的取值范围。你可以定义成千上万个线程,逻辑上它们都是独立存在的。
从硬件视角看:并非如此。GPU 的物理资源(如 SM 流式多处理器、寄存器、并行执行单元)是有限的。硬件会根据资源情况,将这些逻辑线程分批次地调度到物理核心上执行。即使你定义了 100 万个线程,硬件也只是通过快速切换和流水线操作,让你“感觉”它们在同时运行。
那么当定义的数量比物理核心数量多时,就一部分、一部分的创建,只是保证thread id还是那么多
对于求数组和的这个问题,我们之前的所有讨论实际上都基于:每个thread对应一个数组元素
也就是说,如果数组有N个元素,我们在调用kernel时,就会像这样去创建:
1
2
3
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
kernel<<<blocksPerGrid, threadsPerBlock>>>(A, B, C, N);
在评估并行算法时,我们引入 Cost(功耗/开销) 的概念: \(\text{Cost} = \text{处理器数量 (P)} \times \text{时间复杂度 (T)}\) 在这里,根据之前给的算法图容易得到,step的数量是O(logN)的,也就是一个线程的复杂度是O(logN),那如果我们创建了N个线程,Cost就是N * logN 了
这并非最佳的Cost
其实也很好理解,线程的数量显然不是越多越好,一个恰当的线程数的值能带来极大的性能提升
我们可以创建 N / logN 个线程,这样乘以复杂度logN后,Cost就是O(N)的了
但此时要注意一个问题,定义线程数量减少,那么一个线程就要负责多个数组元素了,具体的对应关系是什么呢?
其实可以让block的结构不变,这时一个grid中的线程数量减少,要处理N个数组元素,那么自然会出现多个grid(以前只有一个grid)
这样每个thread都去处理各个grid中对应自己的那个元素即可
可以在loaddata时,就直接将各个grid中对应自己的那个元素加起来
1
2
3
4
5
6
7
8
9
10
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x * (blockSize * 2) + threadIdx.x;
unsigned int gridSize = blockSize * 2 * gridDim.x;
sdata[tid] = 0;
while (i < n) {
sdata[tid] += g_idata[i] + g_idata[i + blockSize];
i += gridSize;
}
__syncthreads();
这样做的优势:
- 解耦性:线程块的数量不再受限于数组长度 N。
- 可扩展性:同一份代码可以根据不同的硬件(SM 数量不同)自动调整负载。
- 效率:通过让每个线程在进入共享内存规约前先处理多个元素的累加,极大地减少了线程间同步的开销。
Warp 级洗牌函数
从 Volta 架构(GV100, RTX 20系列)开始,NVIDIA 引入了独立线程调度(Independent Thread Scheduling)。这意味着 Warp 内的 32 个线程不再总是步调一致地执行——每个线程拥有独立的程序计数器(PC),可以独立分支。
在这种情况下,如果需要获取同一 Warp 内其他线程的变量值,可以使用 Warp 级洗牌函数(Shuffle Functions),直接在寄存器层面交换数据,比通过共享内存更高效。
__shfl_down_sync() 函数
函数原型:
1
2
int __shfl_down_sync(unsigned int mask, int var, unsigned int offset,
int width = warpSize);
功能:返回同一 Warp 中 laneId + offset 位置线程的 var 值。
参数说明:
mask:32 位掩码,指定哪些线程参与本次同步(为 1 的位表示参与)var:当前线程要广播的变量值offset:偏移量,当前线程从laneId + offset位置的线程获取var值width:指定 warp 的宽度,默认为 32(warpSize)
[!NOTE] “laneId” 是 Warp 内线程的逻辑编号(0~31),可通过
threadIdx.x % 32或lane_id()内置函数获取。
常见洗牌函数变体:
__shfl_sync():从指定 lane ID 获取值__shfl_up_sync():从编号更小的线程获取值__shfl_xor_sync():通过异或运算确定目标线程